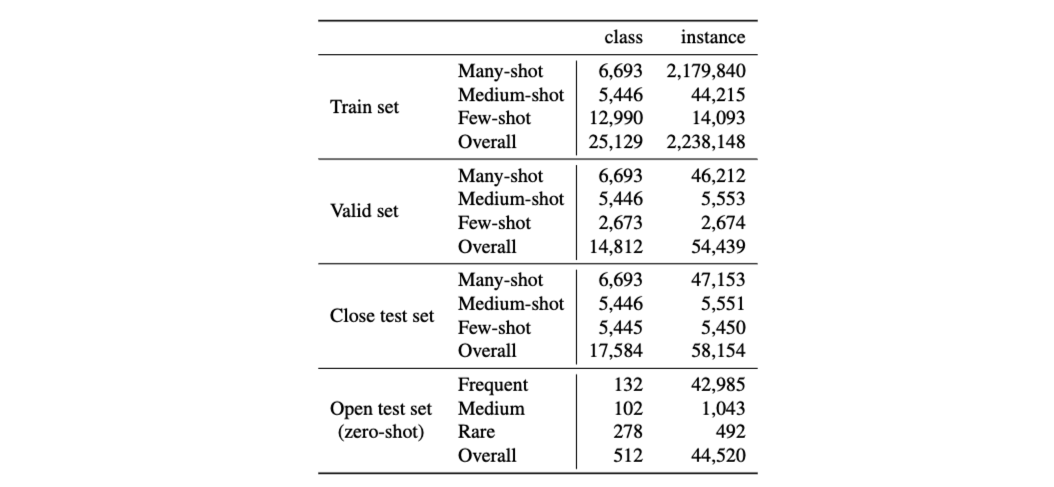
Data Statistics and Examples
LoT-insts contains over 25k classes whose frequencies are naturally long-tail distributed. Its test set from four different subsets: many-, medium-, and few-shot sets, as well as a zero-shot open set. To our best knowledge, this is the first natural language dataset that focuses on this long-tailed and open classification problem.

We partitioned the dataset into different subsets for training and evaluation. The open test set was collected by randomly sampling 2% of the categories. Thus the model will not see any examples from these categories during training. For the two close test set and valid set, we randomly sample 2% of the examples from the remaining data for each of the sets. To better handle few-shot categories, we conduct extra steps to ensure that there is at least one example in training set for each category in the test set, and the test set covers as many categories as possible.